编译 / VRAR星球 R星人
4月18日,在2024中国生成式AI大会上,李未可推出了为智能眼镜等未来AI+终端定向优化的自研WAKE-AI多模态大模型,它具备文本生成、语言理解、图像识别及视频生成等多模态交互能力。

据了解,WAKE-AI多模态大模型融合了人类意图理解和长期记忆机制,可以为用户提供拟人的情感陪伴服务。同时,结合实时的全域数据及LBS信息采集处理,WAKE-AI大模型能够提供准确有效的室外信息检索服务。
WAKE-AI使用MOE架构,FlashAttention混合精度训练、知识蒸馏等技术大幅降低算力需求跟计算时间。值得一提的是,该大模型针对眼镜端用户的使用方式、场景等进行了优化。例如,在语音返回速度上能做到<500ms以内,语音唤醒的准确度>90%,ASR字错率低于2%。
有消息称,李未可将于近期正式发布搭载WAKE-AI多模态大模型的新终端,我们VRAR星球也将对此表示持续关注。
商务合作:13146398132
媒体合作:13341147250
爆料投稿:editor@vrarworld.cn
版权声明:本文为VRAR星球原创,任何单位及个人未经授权不得转载,否则将依法追究侵权责任。
如需转载请联系13341147250 / editor@vrarworld.cn 申请授权,转载时请注明来源并保留VRAR星球原文链接。
本文部分图片及视频来源于互联网,如涉及侵权请联系我们删除。

2024年8月 | 全国VR/AR行业政策汇总

科技赋能科学教育,红网VR大视界亮相2025中国新媒体大会

锐评 | 这家XR厂商太厉害:美军是客户,产品远销40多个国家

这项VR技术将可以重现过去,让你沉浸式地进入回忆中
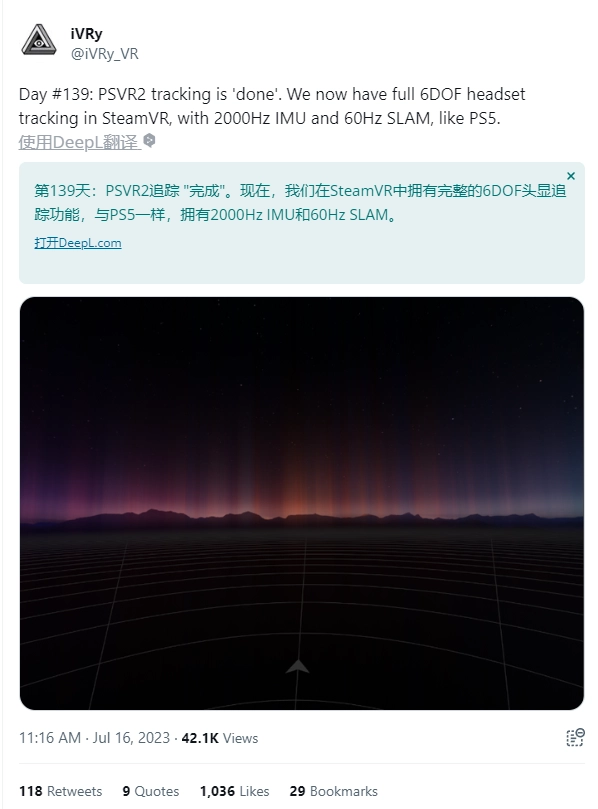
PS VR2头显有望将与PC兼容,并实现破解6DOF跟踪功能
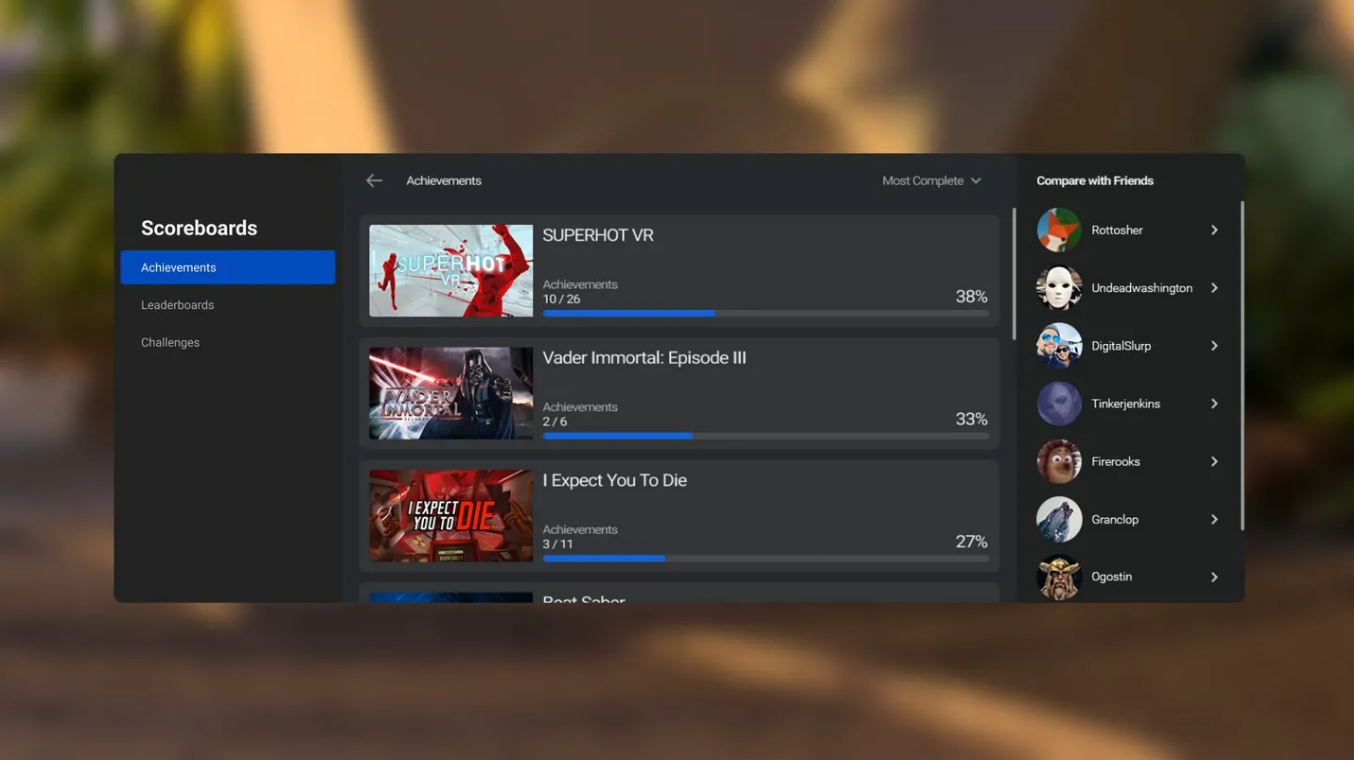
Meta移除用于查看Quest全球成就排名的应用程序,引起开发者和用户不满

由于数字广告市场的下滑,Snap计划裁员约10%

高通推出Snapdragon Seamless跨平台技术

外国商业研究公司锐评全球眼镜行业:小米、XREAL、Rokid等中国企业上榜

华为逐步完成全部功能测试用例,可支撑XR、AI等业务需求

关注微信公众号

扫码添加客服