3月27日凌晨,阿里巴巴发布并开源首个端到端全模态大模型通义千问Qwen2.5-Omni-7B,可同时处理文本、图像、音频和视频等多种输入,并实时生成文本与自然语音合成输出。在权威的多模态融合任务OmniBench等测评中,Qwen2.5-Omni刷新业界纪录,全维度远超Google的Gemini-1.5-Pro等同类模型。
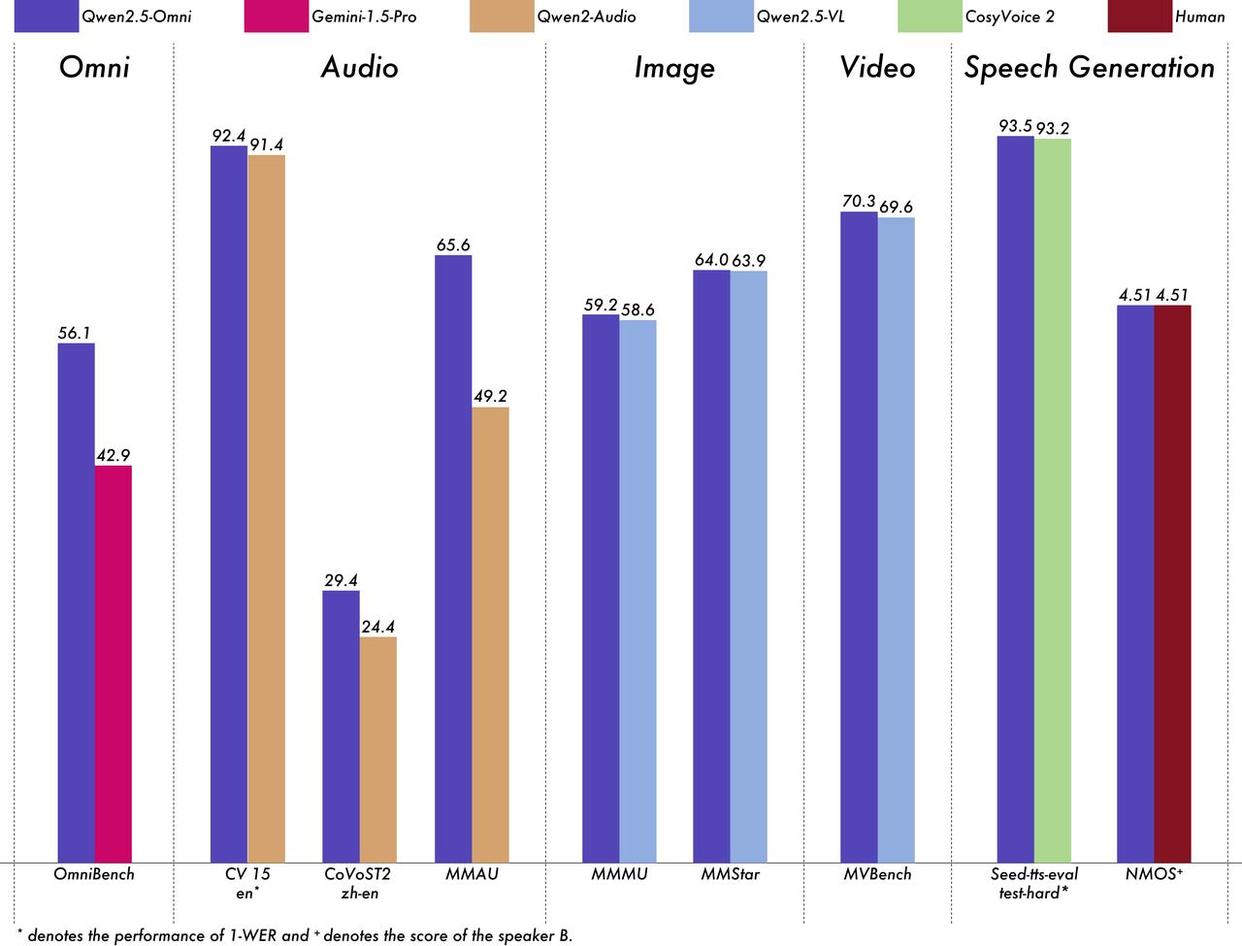
性能测评对比,图源:网络
据了解,Qwen2.5-Omni以接近人类的多感官方式“立体”认知世界并与之实时交互,还能通过音视频识别情绪,在复杂任务中进行更智能、更自然的反馈与决策。现在,开发者和企业可免费下载商用Qwen2.5-Omni,手机等终端智能硬件也可轻松部署运行。
Qwen2.5-Omni采用了通义团队全新首创的Thinker-Talker双核架构、Position Embedding (位置嵌入)融合音视频技术、位置编码算法TMRoPE(Time-aligned Multimodal RoPE)。双核架构Thinker-Talker让Qwen2.5-Omni拥有了人类的“大脑”和“发声器”,形成了端到端的统一模型架构,实现了实时语义理解与语音生成的高效协同。具体而言,Qwen2.5-Omni支持文本、图像、音频和视频等多种输入形式,可同时感知所有模态输入,并以流式处理方式实时生成文本与自然语音响应。
得益于上述突破性创新技术,Qwen2.5-Omni在一系列同等规模的单模态模型权威基准测试中,展现出了全球最强的全模态优异性能,其在语音理解、图片理解、视频理解、语音生成等领域的测评分数,均领先于专门的Audio或VL模型,且语音生成测评分数(4.51)达到了与人类持平的能力。(新闻来源:钱江晚报)
商务合作:13146398132
媒体合作:13341147250
爆料投稿:editor@vrarworld.cn
版权声明:本文为VRAR星球原创,任何单位及个人未经授权不得转载,否则将依法追究侵权责任。
如需转载请联系13341147250 / editor@vrarworld.cn 申请授权,转载时请注明来源并保留VRAR星球原文链接。
本文部分图片及视频来源于互联网,如涉及侵权请联系我们删除。
马斯克:“地球上最聪明的AI” Grok 3大模型即将发布

阿里首款自研AI眼镜正式发布,含带显示和不带显示两款,支持高德导航、支付宝看一下支付等功能

卖3999元!阿里夸克 AI 眼镜凭什么比小米贵一倍?

马云重回后,阿里将长远目光投向了AR

苹果与阿里将合作开发面向中国iPhone用户的AI功能

AI眼镜二季度大战打响:华为、阿里、字节跳动等巨头的新动态全揭秘

消息称谷歌老将吴永辉加入字节,专注大模型基础研究探索

大模型的尽头是小电池:AI眼镜的电池为何能限制它的智能水平?

工业和信息化部:加强通用大模型和行业大模型研发布局

阿里独家合作,亚马逊“亲测”代言,雷鸟创新打造 AI 眼镜新标杆,媲美 Meta !


谷歌发布了视频生成AI“Gemini Omni Flash”,现可通过Gemini API使用

天马推出全球首款3.16英寸Micro-LED透明圆屏

谷东智能PVG研发取得新突破:光波导少一层,视场扩大到45°

Solos发布AirGo A6智能眼镜,主打轻量化与隐私保护,AirGo V2同步全球开售

Raontech获海外AR眼镜LCoS开发合同,总价值最高达77亿韩元

千问AI眼镜迎来版本更新:高德打车、外卖闪购等重磅功能上线,打造全天候智能生活助手

高效黄光LED AR眼镜,获得国家科学技术奖一等奖!

苹果停止开发平价XR显示器项目,三星显示终止相关研发

中交四航院 VR技术解锁智慧港口升级新场景
谷歌发布了视频生成AI“Gemini Omni Flash”,现可通过Gemini API使用
天马推出全球首款3.16英寸Micro-LED透明圆屏
谷东智能PVG研发取得新突破:光波导少一层,视场扩大到45°
Solos发布AirGo A6智能眼镜,主打轻量化与隐私保护,AirGo V2同步全球开售
Raontech获海外AR眼镜LCoS开发合同,总价值最高达77亿韩元
千问AI眼镜迎来版本更新:高德打车、外卖闪购等重磅功能上线,打造全天候智能生活助手
高效黄光LED AR眼镜,获得国家科学技术奖一等奖!
苹果停止开发平价XR显示器项目,三星显示终止相关研发
中交四航院 VR技术解锁智慧港口升级新场景

关注微信公众号

扫码添加客服


