4 月 7 日消息,Meta 公司上周发布了一款名为 Maverick 的新旗舰 AI 模型,并在 LM Arena 测试中取得了第二名的成绩。然而,这一成绩的含金量却引发了诸多质疑。据多位 AI 研究人员在社交平台 X 上指出,Meta 在 LM Arena 上部署的 Maverick 版本与广泛提供给开发者的版本并不一致。
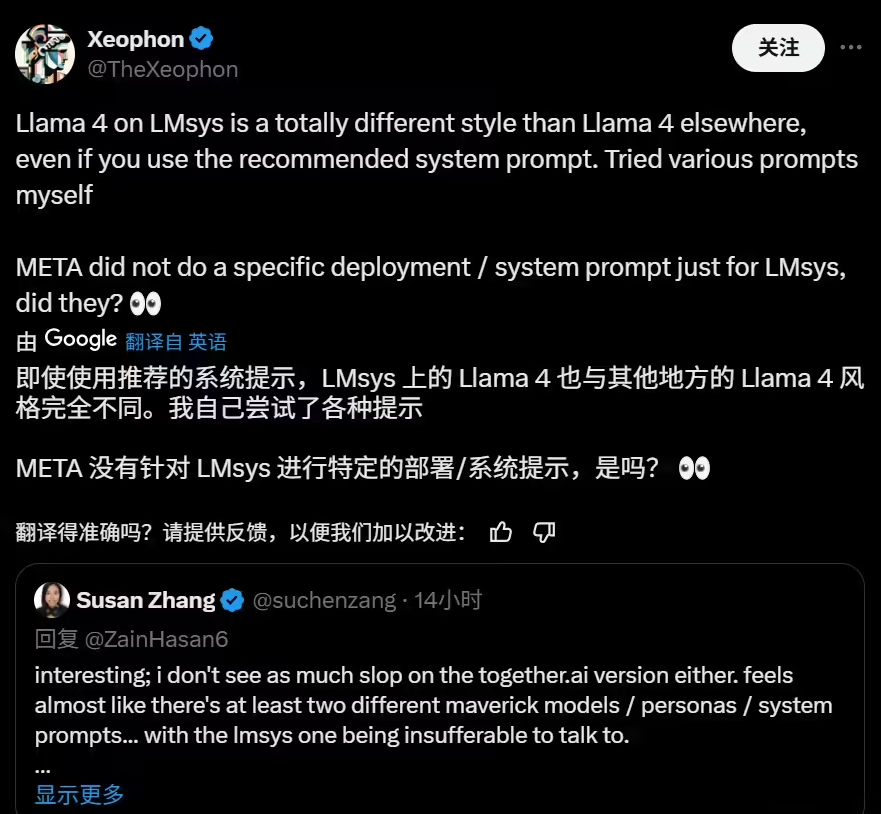
据悉,Meta 在其公告中明确提到,参与 LM Arena 测试的 Maverick 是一个“实验性聊天版本”。而根据官方 Llama 网站上公布的信息,Meta 在 LM Arena 的测试中所使用的实际上是“针对对话性优化的 Llama 4 Maverick”。这表明,该版本经过了专门的优化调整,以适应 LM Arena 的测试环境和评分标准。
然而,LM Arena 作为一项测试工具,其可靠性本身就存在一定的争议。尽管如此,以往 AI 公司通常不会对模型进行专门的定制或微调,以在 LM Arena 上获得更高的分数,至少没有公开承认过这种做法。
这种对模型进行针对性优化,然后只发布一个“普通版”的行为,给开发者带来了诸多困扰。因为这使得开发者难以准确预测该模型在特定场景下的实际表现。
目前,Meta 公司以及负责维护 LM Arena 的 Chatbot Arena 组织暂未对此做出回应。(新闻来源:IT之家)
商务合作:13146398132
媒体合作:13341147250
爆料投稿:editor@vrarworld.cn
版权声明:本文为VRAR星球原创,任何单位及个人未经授权不得转载,否则将依法追究侵权责任。
如需转载请联系13341147250 / editor@vrarworld.cn 申请授权,转载时请注明来源并保留VRAR星球原文链接。
本文部分图片及视频来源于互联网,如涉及侵权请联系我们删除。


三星首款AI眼镜Galaxy Glasses亮相:无屏显,长续航,强AI

闪极将在全国最大的万象城开设一家AI眼镜旗舰店

Halliday发布第二代AI眼镜:AI可实时参与会议

AI让健康触手可及|生生纪携 AI 心探、本若岚亮相 2026 世界人工智能大会

LumiMind亮相2026世界人工智能大会:从脑电技术到睡眠体验,探索神经科技消费化新路径

AR+AI走进真实场景,亮亮视野在WAIC展示系统化产业应用能力

端侧智能让穿戴设备更“懂你”

WAIC 2026爆款复盘:趣致集团Q-Gen引擎10分钟生成AI营销短剧,内容生产的“最后一公里”被踏平了

维信诺首次亮相ChinaJoy展会,OLED显示龙头加码数字娱乐新场景
三星首款AI眼镜Galaxy Glasses亮相:无屏显,长续航,强AI
闪极将在全国最大的万象城开设一家AI眼镜旗舰店
Halliday发布第二代AI眼镜:AI可实时参与会议
AI让健康触手可及|生生纪携 AI 心探、本若岚亮相 2026 世界人工智能大会
LumiMind亮相2026世界人工智能大会:从脑电技术到睡眠体验,探索神经科技消费化新路径
AR+AI走进真实场景,亮亮视野在WAIC展示系统化产业应用能力
端侧智能让穿戴设备更“懂你”
WAIC 2026爆款复盘:趣致集团Q-Gen引擎10分钟生成AI营销短剧,内容生产的“最后一公里”被踏平了
维信诺首次亮相ChinaJoy展会,OLED显示龙头加码数字娱乐新场景

关注微信公众号

扫码添加客服