编译 / VRAR星球 R星人
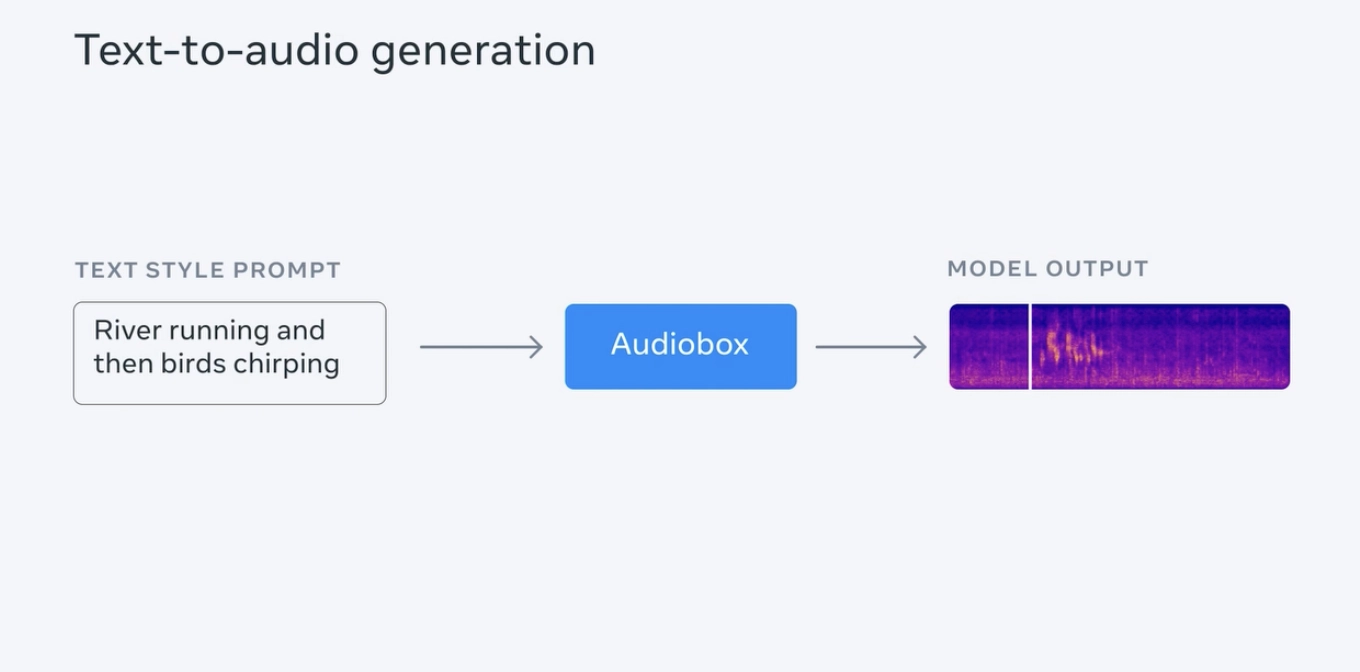
Meta日前推出了一款AI声音生成模型Audiobox,能够同时接收语音及文字输入,用户可同时使用语音及文字描述,让这款模型生成所需的音频。据悉,这款模型基于Meta今年6月推出的Voicebox AI模型,据称Audiobox能生成各种环境音、自然对话语音,并整合了音频生成和编辑能力,以便于用户自由生成自己所需的音频。
图源:ai.meta
Meta介绍称,生成高品质音频需要有大量音频库及深厚的领域知识,但大众难以获得这些资源,而该公司推出这个模型旨在降低声音生成门槛,让任何人都更容易制作视频、游戏等应用场景的音效。
这款Audiobox模型基于Voicebox的“引导声音”机制,以便于生成目标音频,并配合“流量比对(flow-matching)”扩散模型生成方法,以实现“声音填充(audio infilling)”功能,从而生成多层次的音频。
商务合作:13146398132
媒体合作:13341147250
爆料投稿:editor@vrarworld.cn
版权声明:本文为VRAR星球原创,任何单位及个人未经授权不得转载,否则将依法追究侵权责任。
如需转载请联系13341147250 / editor@vrarworld.cn 申请授权,转载时请注明来源并保留VRAR星球原文链接。
本文部分图片及视频来源于互联网,如涉及侵权请联系我们删除。

Meta正式停止支持初代Quest VR头显,不再提供安全更新和修复

Meta CTO表示,Meta的新款EMG腕带不会取代Quest控制器

Meta将在洛杉矶开设智能眼镜线下旗舰店

新证据表明Meta仍在为Quest开发PC VR云游戏流媒体

Meta完成对语音AI初创企业PlayAI收购,全公司本周加入Meta

Meta全新高端智能眼镜售价或超1000美元;国产AI眼镜有望在Q2迎来大规模发布;西安成立全国首支XR发展基金
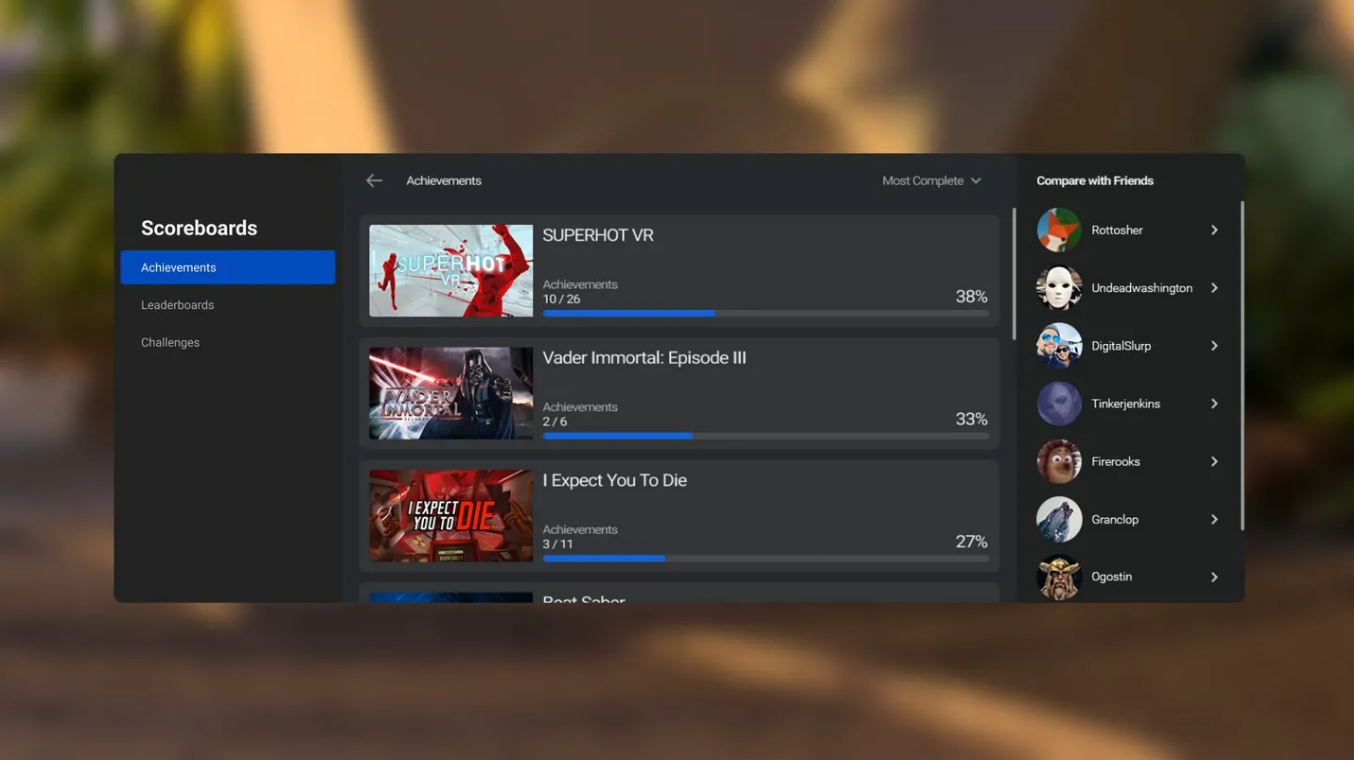
Meta移除用于查看Quest全球成就排名的应用程序,引起开发者和用户不满

Meta官方:Quest 3拥有Quest系列的最高分辨率

KIWI Design加入Meta “Made for Meta”生产计

Meta面临诉讼,指控Ray-Ban智能眼镜向海外评测人员发送私人视频


三星首款AI眼镜Galaxy Glasses亮相:无屏显,长续航,强AI

闪极将在全国最大的万象城开设一家AI眼镜旗舰店

Halliday发布第二代AI眼镜:AI可实时参与会议

AI让健康触手可及|生生纪携 AI 心探、本若岚亮相 2026 世界人工智能大会

LumiMind亮相2026世界人工智能大会:从脑电技术到睡眠体验,探索神经科技消费化新路径

AR+AI走进真实场景,亮亮视野在WAIC展示系统化产业应用能力

端侧智能让穿戴设备更“懂你”

WAIC 2026爆款复盘:趣致集团Q-Gen引擎10分钟生成AI营销短剧,内容生产的“最后一公里”被踏平了

维信诺首次亮相ChinaJoy展会,OLED显示龙头加码数字娱乐新场景
三星首款AI眼镜Galaxy Glasses亮相:无屏显,长续航,强AI
闪极将在全国最大的万象城开设一家AI眼镜旗舰店
Halliday发布第二代AI眼镜:AI可实时参与会议
维信诺首次亮相ChinaJoy展会,OLED显示龙头加码数字娱乐新场景

数智赋能组织管理,莫界与北森达成生态战略合作

苹果Apple Park游客中心启动升级改造,AR展览区暂时关闭

多伦多大学研究:VR会扭曲人对自己身体尺寸的感知

华泰证券:AI眼镜有望成为AI Agent进入物理世界的高频入口
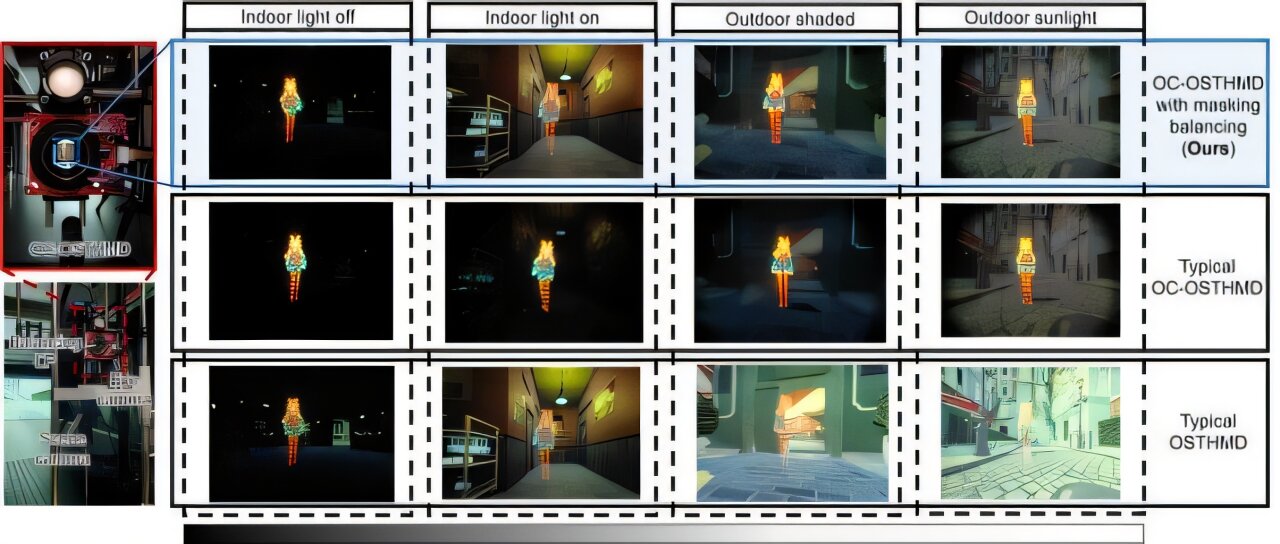
中日联合研究团队发明新型AR显示技术,可在提升现实世界可视性的同时保持虚拟物体的逼真度

关注微信公众号

扫码添加客服


