编译 / VRAR星球 R星人
11月26日消息,据报道,英伟达展示了一种用于生成音乐和音频的新型人工智能模型Fugatto,它可以修改声音并生成新的声音。

Fugatto的独特魅力在于其超越传统的人工智能界限,不仅能够接收并分析现有音频素材,还能对其进行灵活修改。
举例来说,它能将钢琴伴奏的旋律无缝转化为动人的人声演唱,或是调整口语录音中的口音特征与情感色彩,展现出前所未有的音频转换能力。
尽管英伟达目前尚未规划将此技术面向公众开放,但Fugatto在合成音频领域的潜在应用及其可能带来的变革,已引起了业界的广泛瞩目与热烈讨论。
然而,随着生成式人工智能模型的快速发展,其创建者也面临着如何有效防止技术滥用的挑战。特别是如何阻止用户利用此类技术制造误导性信息,或是通过生成受版权保护的角色与内容来侵犯他人权益,成为亟待解决的问题。
此外,行业内的其他巨头如OpenAI与Meta,对于何时会推出能够生成音频或视频的先进模型,同样保持着神秘的态度,尚未透露具体的时间表。
商务合作:13146398132
媒体合作:13341147250
爆料投稿:editor@vrarworld.cn
版权声明:本文为VRAR星球原创,任何单位及个人未经授权不得转载,否则将依法追究侵权责任。
如需转载请联系13341147250 / editor@vrarworld.cn 申请授权,转载时请注明来源并保留VRAR星球原文链接。
本文部分图片及视频来源于互联网,如涉及侵权请联系我们删除。

长盈精密:目前重要客户的AI/AR眼镜正在开发当中

元宇宙项目Mars4.me获DWF Labs长期财务支持,将推动AI驱动的元宇宙开发

迪士尼成立技术赋能办公室 探索AI、MR等新兴技术

Stability AI发布新模型Stable Virtual Camera,2D照片轻松转3D视频

Flyme AIOS 媒体沟通会:星纪魅族携手生态好友,AI 点亮美好生活

古尔曼:苹果机器人首席AI研究员跳槽至Meta,多名核心研究人员离职

谷歌地图新增AR视图

Open AI官宣:已开始训练下一代大模型,取代GPT-4

Rokid获批国家重点研发专项,联手中国眼谷普惠数亿眼健康人群
谷歌Gemini 2.5 Flash混合推理AI模型上线:性能成本双优


三星首款AI眼镜Galaxy Glasses亮相:无屏显,长续航,强AI

闪极将在全国最大的万象城开设一家AI眼镜旗舰店

Halliday发布第二代AI眼镜:AI可实时参与会议

AI让健康触手可及|生生纪携 AI 心探、本若岚亮相 2026 世界人工智能大会

LumiMind亮相2026世界人工智能大会:从脑电技术到睡眠体验,探索神经科技消费化新路径

AR+AI走进真实场景,亮亮视野在WAIC展示系统化产业应用能力

端侧智能让穿戴设备更“懂你”

WAIC 2026爆款复盘:趣致集团Q-Gen引擎10分钟生成AI营销短剧,内容生产的“最后一公里”被踏平了

维信诺首次亮相ChinaJoy展会,OLED显示龙头加码数字娱乐新场景
三星首款AI眼镜Galaxy Glasses亮相:无屏显,长续航,强AI
闪极将在全国最大的万象城开设一家AI眼镜旗舰店
Halliday发布第二代AI眼镜:AI可实时参与会议
维信诺首次亮相ChinaJoy展会,OLED显示龙头加码数字娱乐新场景

数智赋能组织管理,莫界与北森达成生态战略合作

苹果Apple Park游客中心启动升级改造,AR展览区暂时关闭

多伦多大学研究:VR会扭曲人对自己身体尺寸的感知

华泰证券:AI眼镜有望成为AI Agent进入物理世界的高频入口
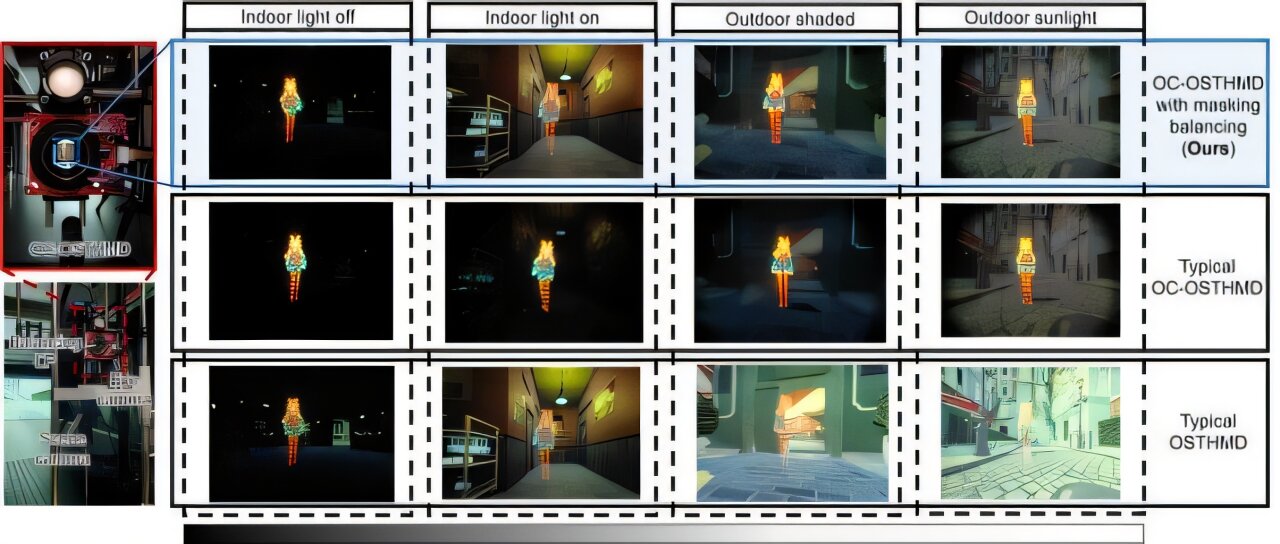
中日联合研究团队发明新型AR显示技术,可在提升现实世界可视性的同时保持虚拟物体的逼真度

关注微信公众号

扫码添加客服


